Introduction
Analytic databases are the industry standard for maintaining large data sets. As a data practitioner, it is essential to interact with these databases. The octopus package aims to be the default tool for interacting with and managing databases.
Multilingual Support
One of the most important goals of the octopus package is multilingual support for various databases. The name octopus analogizes the many arms of an octopus to the many compatible connection types of the package.
Under the hood, the octopus package starts a shiny application that receives input from the browser. It takes that input and translates it to the specific SQL dialect for the database you are working with.
Take, for example, the following two ways of querying data from a table. In Postgres, you would specify the exact table name using quotations.
However, in MySQL you would specify the exact table name using back ticks.
Subtle differences like this can be annoying to remember, but you can simply click the View button in the octopus interface and you will get a preview of the table regardless of the SQL dialect.
Here is a list of the currently supported databases.
octopus::list_drivers()
#> [1] "PqConnection" "Snowflake" "Vertica Database"
#> [4] "duckdb_connection" "MySQLConnection" "SQLiteConnection"
#> [7] "Microsoft SQL Server"Comparison to DBI
Let’s demonstrate how to explore a database using the DBI package alone versus using the octopus package. Let’s begin by connecting to a MySQL database that we want to explore.
con <- DBI::dbConnect(
RMySQL::MySQL(),
host = "localhost",
user = "sakila",
password = "p_ssW0rd",
dbname = "sakila",
port = 3306
)We can list all the tables available in the database by using
DBI::dbListTables().
DBI::dbListTables(con)
# [1] "actor" "actor_info"
# [3] "address" "category"
# [5] "city" "country"
# [7] "customer" "customer_list"
# [9] "film" "film_actor"
# [11] "film_category" "film_list"
# [13] "film_text" "inventory"
# [15] "language" "nicer_but_slower_film_list"
# [17] "payment" "rental"
# [19] "sales_by_film_category" "sales_by_store"
# [21] "staff" "staff_list"
# [23] "store"To see the details of a table we can use
DBI::dbReadTable() to read the entire table into our R
session.
DBI::dbReadTable(con, "actor") |> head()
# actor_id first_name last_name last_update
# 1 1 PENELOPE GUINESS 2006-02-15 04:34:33
# 2 2 NICK WAHLBERG 2006-02-15 04:34:33
# 3 3 ED CHASE 2006-02-15 04:34:33
# 4 4 JENNIFER DAVIS 2006-02-15 04:34:33
# 5 5 JOHNNY LOLLOBRIGIDA 2006-02-15 04:34:33
# 6 6 BETTE NICHOLSON 2006-02-15 04:34:33Using this approach works fine for a single table, but what if we want to view many tables, or even different schemas? We would need to copy and paste our code and change the table name each time.
Rewriting our code repeatedly becomes tedious; especially if we don’t know exactly where the data is in the database that we need.
Octopus Approach
Let’s try a different approach. Let’s use octopus to interact with the database through the application interface.
# Start the octopus app
octopus::view_database(con)
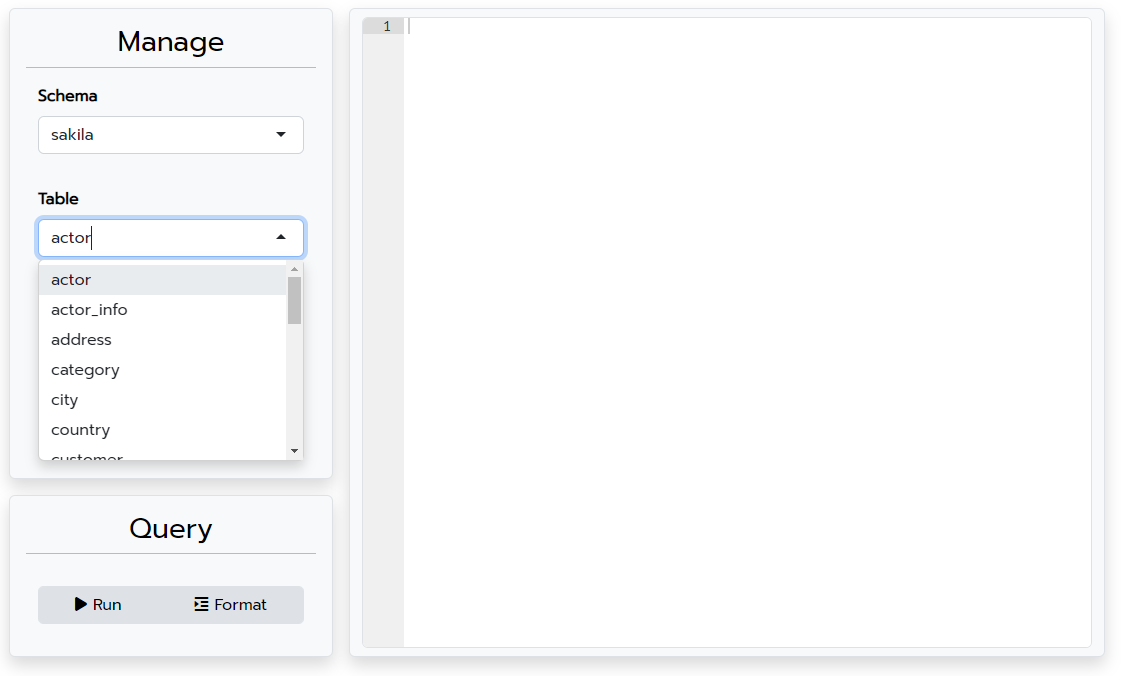
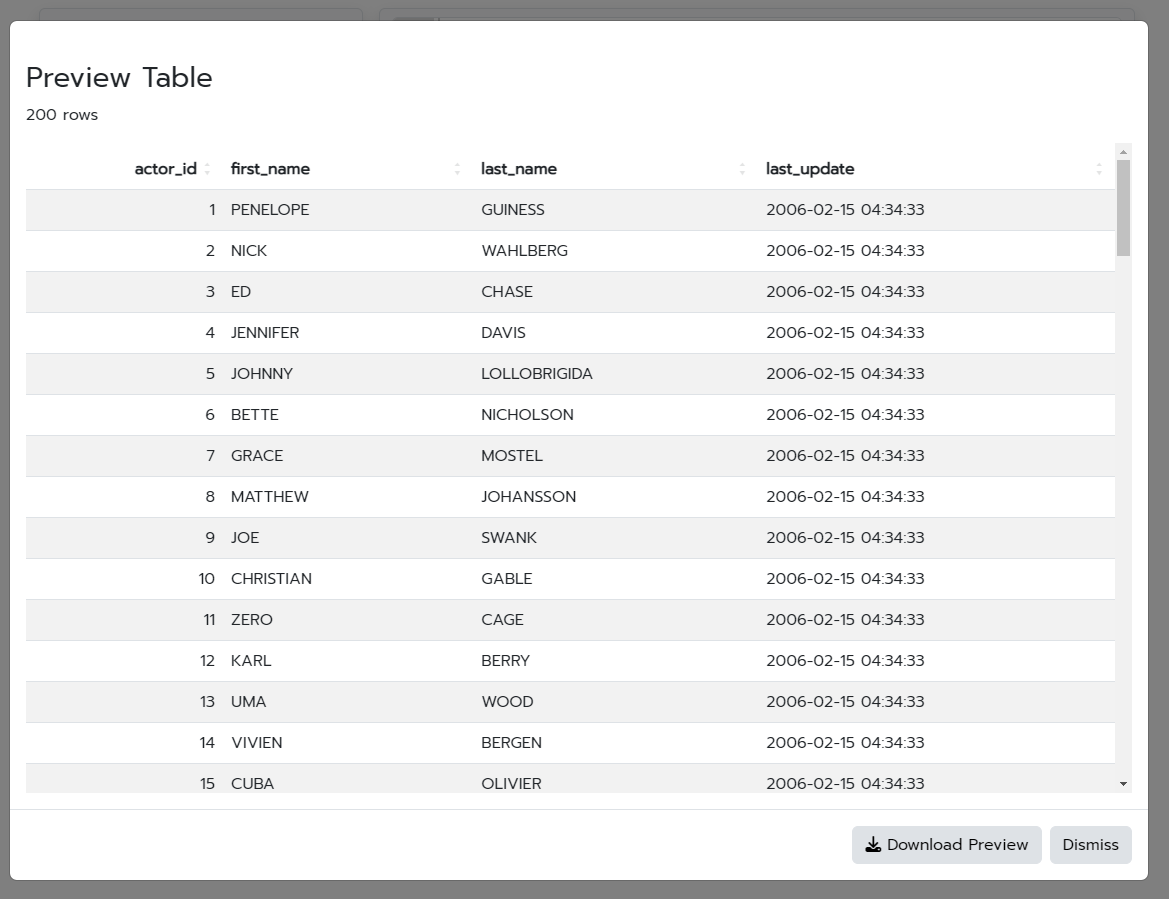
Now we can easily scroll through the different tables in the database and preview them using the View button. We also know exactly how many rows a table has without having to bring the data into our R session.